Some Message Broker Throughput Techniques
Message Queuing at it's finest point is an art-form. It shouldn't be, of course, but it is. Most people won't need too high a quality of artist to work on their message system but, at the highest level of requirements you're going to need a Van Gogh working with you :-)
I'm going to describe here a few pointers as to what to do when the message producers in a system are producing messages quicker than the consumers can process them or, as I would prefer to say, 'the consumers are processing the messages too slowly' ;-)


I'm going to describe here a few pointers as to what to do when the message producers in a system are producing messages quicker than the consumers can process them or, as I would prefer to say, 'the consumers are processing the messages too slowly' ;-)
Problem Statement
The fundamental of any high-throughput asynchronous messaging system is that messages need to be handled quickly by the back-end consumers. If consumers don't do their job quickly enough then queue depths start to increase.
It is, in messaging terms, quite a high-speed operation to put messages on to a queue, it takes longer to remove messages from the queue. This is due to internal locking schemas as well as indexing issues - i.e. the bigger the queue, the bigger the index. Therefore, large queue depths are not a good thing to have, in most cases.
There are clearly two things that can be done to help a messaging system that is struggling to keep up with load. Either, add more consumers or slow down the producers.
Producer Throttling
JMS and other messaging protocols have taken the latter route by adding capabilities that will throttle the message producer if the underlying messaging system is struggling to cope for whatever reason. However, throttling should only ever be seen as a temporary solution. After all, what is the message producer going to do with it's messages - throw them away? Backlog them until it gets told that the messaging system can cope again? (in which case it may well end up failing itself if the outage is too long).
Throttling producers is fine as long as the messaging pipeline is slowing temporarily e.g. a consumer has failed temporarily but will come back on-line. In addition, the producers must be able to cope with the excess load on their end; whether that means being allowed to throw messages away or having the capability of storing message until such times as they get the green light from the server.
Adding Message Consumers
Adding Message consumers is really the only way to handle an overloaded messaging system where the queues are full to bursting. However, as was just identified above, as a queue gets larger the effort, and therefore time, it takes to get a message from the queue and give it to the consumers increases due to locking and indexing paradigms.
This means that only so many consumers can read from the same queue before the queue begins to lock-up under the weight of the throughput. This is where clustered queueing comes into the equation.
Clustered Message Brokers
Clustering is an oft used term in messaging and computing in general but... be aware. Rarely does the term mean the same thing twice when it comes to different messaging providers !
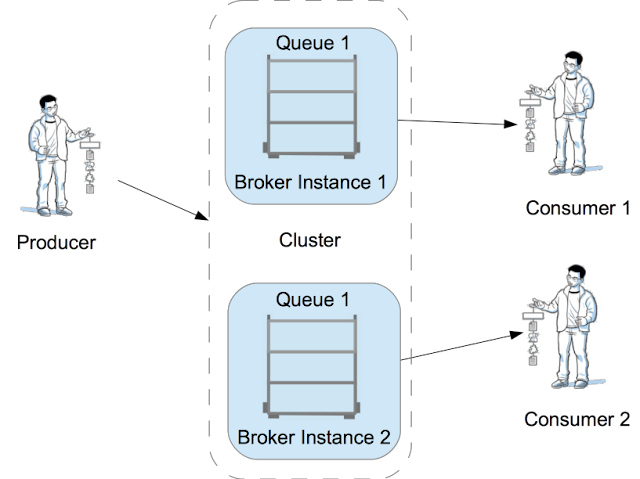
Although clustering can come in many forms; for the purposes of this blog I will assume that we are talking about the ability for a producer to put a message to a queue and for that message to appear on one of many different message brokers (or Queue managers in IBM parlance).

The diagram above shows a single message producer connecting to 'the cluster' and putting messages to Queue 1. The consumers also connect to 'the cluster' however, the clustering system has distributed the underlying connection to one of the 2 broker instances in order to reduce load on any specific broker. (Clearly this is a theoretical diagram and we could really be talking about hundreds or even thousands of producers and consumers in an extreme situation.)
In the above scenario the broker cluster distributes messages from the producers so that they appear on 'queue 1' on either message broker 1 or message broker 2. The broker does this so that the expensive operation of removing messages from the queue is distributed across both broker nodes. This distribution mechanism depends heavily on what messaging provider you are using. IBM MQ, for instance, distributes messages using a round-robin algorithm. So, message 1 would appear on Broker 1 and Message 2 would appear on broker 2. However, each provider is different (assuming they even support this pattern).
Some of you may be thinking that moving messages is a very expensive operation. You'd be right, however, it's not as expensive as consumers taking messages from queues. It also helps if there are multiple message producers and they are also load balanced across servers. In the case of multiple producers they may be configured (either deliberately or by the messaging provider) to only send messages to the broker instance they are connected to thus, hopefully, avoiding messages being transmitted between brokers.
Message Instances
The case I described above has an algorithm to move messages from one broker to another in order to distribute the load to the consumers. This algorithm assumes that there is only one instance of the message i.e. that at any one point in time only one instance of that message is physically within the entire broker cluster network and can therefore only be processed by one consumer.
There are alternatives to this strategy. Some message providers actually duplicate the messages and put one instance of the message on queue 1/broker 1 and one instance of the message on queue 2/broker 2. In this case there has to be a locking mechanism to ensure that two consumers do not get the same message -this is often done using shared disk.

Having this sort of capability is a risky strategy: locking across brokers is a tricky and time consuming business. However, the rewards are that if one broker fails or the consumers on the broker fail there will be another a broker with a consumer who can process the message.
There are optimisations to this. One such optimisation being that the messages stay on whatever queue they got put to but the act of a consumer requesting a message from an empty queue sends the message provider scurrying away to get a message to that queue asap. This is a very complex operation if one considers message selection algorithms, optimisation of network usage versus waiting for a local consumer etc. etc.
As I said at the beginning clustering means a lot of different things to messaging providers and most providers go either for the single message instance strategy or for multiple instances of the same message. I know that IBM WebSphere Application Server's internal messaging engine (SI Bus) can be configured to either keep single instance of messages or have movement of messages across instances. It is clearly documented that the penalty for choosing the moving messages strategy is latency and throughput.
The Multi-layered Queue Manager Architecture
The architecture shown below is a variation on the clustered architecture. The architecture consists of one or more Message brokers (Queue Managers in IBM MQ terms) at the front-end. These then quickly move messages on to multiple back-end systems which is where the consumers connect to.

This strategy relies on two things
- QM1 cannot take the load of all the consumers
- Moving messages from QM1 to QM2 and QM3 is an automated process and takes little resource to do.
In some extremely heavily loaded systems there may be three or more tiers before the brokers can take the load of the consumers without buckling.
Summary
We have seen that messaging is all about making sure that there are enough consumers for the load being produced. To not have enough consumers is suggesting that messages can get thrown away, lost or delayed.
Consuming messages is more intensive an operation than publishing them and therefore distribution of consumers across multiple brokers is necessary in larger scale architectures. However, there is always a trade off between messages moving between systems, and therefore being guaranteed to be consumed, versus waiting for consumers to come to the location of the message.



Comments
Post a Comment